Apache Pulsar高可用设计

Pulsar 集群包含 3 个组件:ZooKeeper 集群、BookKeeper 集群和 Broker 集群。
其中BookKeeper做消息的存储,Broker做消息的处理计算,Pulsar依靠BookKeeper,实现了「存储计算分离」的架构,这是有别于其他MQ最大的一点。还有一个ZooKeeper主要是存储Broker和BookKeeper的元数据,以及Pulsar clusar的集群配置协调工作。
在 Apache Pulsar 的分层架构中,服务层 Broker 和存储层 BookKeeper 的每个节点都是对等的。Broker 仅仅负责消息的服务支持,不存储数据。这为服务层和存储层提供了瞬时的节点扩展和无缝的失效恢复。
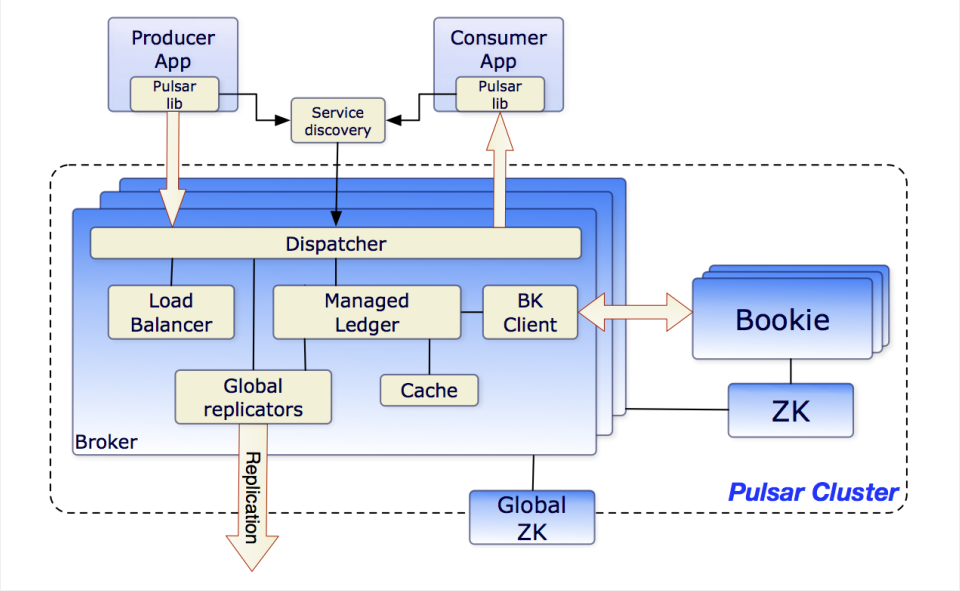
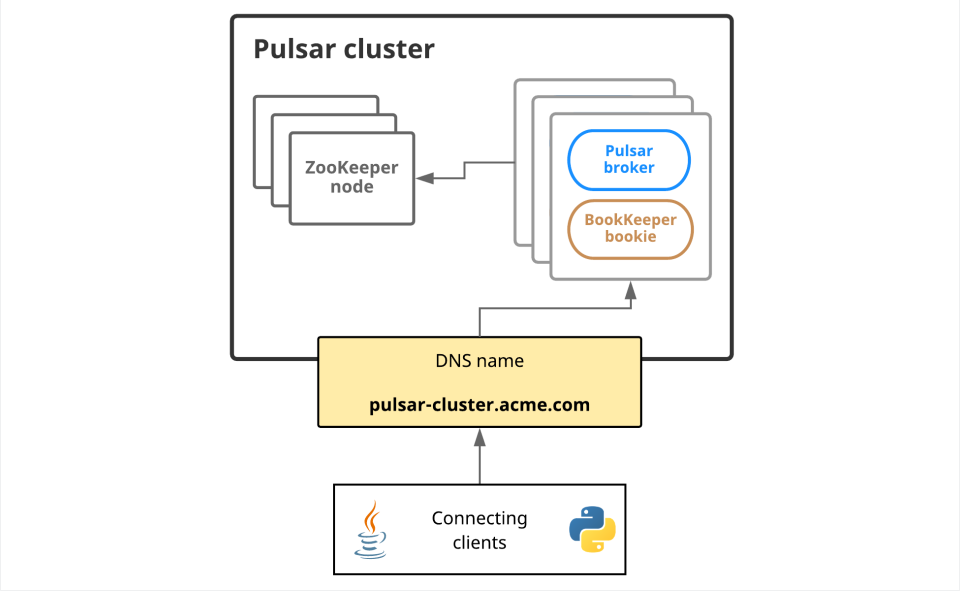
ZooKeeper 集群高可用
一个 ZooKeeper 集群通常由一组机器组成,一般 3 台以上就可以组成一个可用的 ZooKeeper 集群。
组成 ZooKeeper 集群的每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都会互相保持通信。
只要集群中存在超过一半的机器能够正常工作,那么整个集群就能够正常对外服务。
基于这个特性,如果想搭建一个能够允许 N 台机器 down 掉的集群,那么就要部署一个由 2*N+1 台服务器构成的 ZooKeeper 集群。因此,一个由 3 台机器构成的 ZooKeeper 集群,能够在挂掉 1 台机器后依然正常工作,而对于一个由 5 台服务器构成的 ZooKeeper 集群,能够对 2 台机器挂掉的情况进行容灾。
Broker 集群高可用
如果一个 Broker 失败,Pulsar 会自动将其拥有的主题分区移动到集群中剩余的某一个可用 Broker 中。需要注意的是:由于 Broker 是无状态的,当发生 Topic 的迁移时,Pulsar 只是将所有权从一个 Broker 转移到另一个 Broker,在这个过程中,不会有任何数据复制发生。
当 client 开始使用未分配给任何Broker的Topic时,将触发一个机制:根据负载条件选择最合适的Broker来获取这些Topic的所有权。
如果是分区主题的情况(partitioned topics),则将不同的分区分配给不同的Broker。此处的“topic”是指未分区的主题或该Topic的一个分区。
分配是“动态的”,因为分配变化很快。例如,如果拥有该Topic的Broker崩溃,则将该Topic立即重新分配给另一个Broker。另一种情况是拥有Topic的Broker变得超载。在这种情况下,将Topic重新分配给负载较小的Broker。需要注意的是:由于 Broker 是无状态的,当发生 Topic 的迁移时,Pulsar 只是将所有权从一个 Broker 转移到另一个 Broker,在这个过程中,不会有任何数据复制发生。
Broker 的无状态性质使动态分配成为可能,因此可以根据使用情况快速扩展或收缩集群。
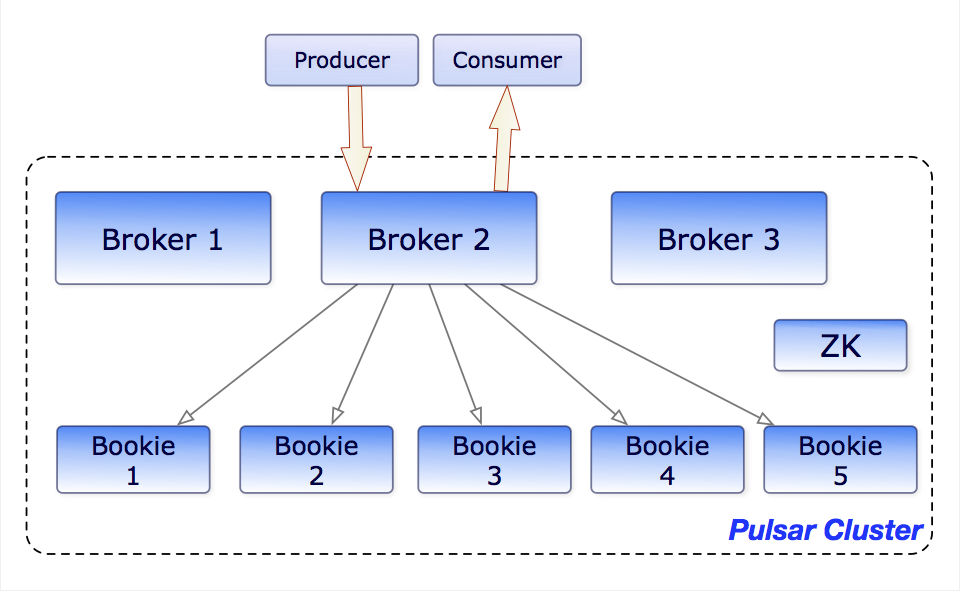
BookKeeper 集群高可用
一个 BookKeeper 集群包括:
Bookies:一组独立的存储服务器Metadata store(元数据存储系统):用于服务发现和元数据管理
存储的配置是以Ledger为单位来管理的,最重要的配置有三个:
Ensemble size (E),全体数量Write quorum size (Qw),写入数量Ack quorum size (Qa),响应数量
全体数量(E):表示Ledger可以写入的总体Bookie池的Bookie数量;写入数量(Qw):表示对于每个Entry,Ledger需要写入的份数;响应数量(Qa):表示当写入返回多少个Ack时,返回给客户端,即写入成功。通常情况下E >= Qw >= Qa。
关键点:
-
BookKeeper将数据存储至集群中的节点上,每个BookKeeper节点称为Bookie。 -
一个
Topic由多个Ledger构成,一个Ledger由一个或多个Fragment组成,每个Fragment有多个条目Entry组成,每个Entry上包含的就是多条消息Message。 -
Fragment是BookKeeper集群中最小的分布单元,Ledger是最小的删除单元。 -
Topic是Pulsar中的概念。Ledger和Fragment是BookKeeper中的概念。 -
每个
Pulsar Broker都需要跟踪每个Topic所包含的Ledgers和Fragments。这个元数据存储在Zookeeper中。 -
Fragments分布在Bookie集群中,跨多个Bookies带状分布。存储可以单独扩展。如果存储是瓶颈,那么只需要添加更多的Bookies,他们会自动承担负载,不需要Rebalance。 -
当
Bookie不可用时,自动恢复模式将自动进行Ledgers数据重新复制到其他的Bookies,以确保每个Ledger副本数达到Qw。 -
BookKeeper通过Quorum Vote的方式来实现数据的一致性,跟Master/Slave模式不同,BookKeeper中每个节点也是对等的,对一份数据会并发地同时写入指定数目的存储节点。对等的存储节点,保证了多个备份可以被并发访问;也保证了存储中即使只有一份数据可用,也可以对外提供服务。

————————————————
原文链接:https://blog.csdn.net/wzt_gjt/article/details/109179822
原文链接:https://jishuin.proginn.com/p/763bfbd398dd
原文链接:https://www.jianshu.com/p/0d55a205a575